Chess AI
Result

Introduction
Lately I (and many others) have been fascinated with the game of chess. Because of my newfound fascination, I have been teaching myself some chess strategies which lead me to learn about the chess-engine Stockfish.
I started to become intrigued by its functionality so I did some digging on the internet. It seemed interesting to me to write my own chess-engine. But first I had to start by making something I little more realistic than to code a neural network right away, namely: a chess AI with the use of the Minimax algorithm and Alpha-Beta pruning.
Minimax
Minimax is a searching algorithm that allows the program to look for future situations and to decide which moves are the most advantageous.
This algorithm works based on a predetermined depth so that the program knows how far it has to look into the future.
You can visualize this by a search tree of which each node is a chess position. To keep it simple I will represent it with a binary search tree.
Let's start with the root node, which represents the current position:

Imagine our AI is playing with the black pieces and it's now the AI's turn to move. To make a decision, we will use the Minimax algorithm using the current position and a predetermined depth.
We'll take a depth of 2. This means that the AI will look 2 steps ahead into the future. Once it reaches that depth, we will evaluate all positions up until that depth is reached based on an evaluation function, eg. the possibility to take the opponent's pieces.
Black has a couple of different options from the position it's currently in:
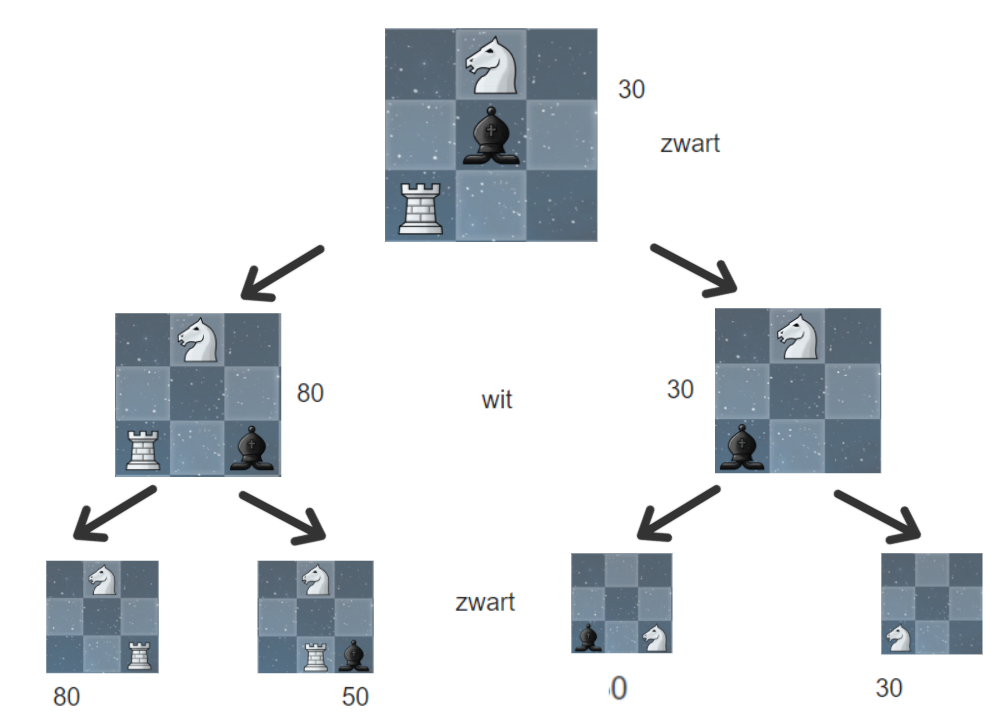
The first thing that happens is the traversal of the left side of the tree until we have reached the given depth (2). Once the algorithm has reached that depth, the program will evaluate all possible positions. This is done by subtracting the sum of values of all black pieces by the sum of values of all white pieces.
Each piece has its own unique value: pawn 10, knight and bishop 30, rook 50, queen 90 and king 900.
If the evaluation function returns a negative value, that means that black (minimizing player) has the advantage. A positive value means that white has the advantage. So if we reach a layer at which it's white's turn to move, white will choose the most positive value it can. If it's black's turn to move, it will pick the most negative evaluation.
Once we have evaluated all positions in the tree, our chess AI will choose the move that is most advantageous for it (in our situation the AI is playing as black so it will choose the most negative evaluation).
That is the Minimax algorithm.
Alpha-Beta pruning
Alpha-Beta pruning is not evaluating certain nodes in the tree which results in the faster use of the Minimax algorithm.
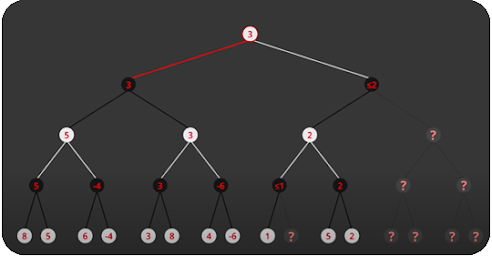
This "not evaluating" of certain nodes happens when we know beforehand that the value of those nodes won't get picked eventually anyway by the Minimax algorithm. In other words we can ignore those nodes AKA "prune" them.
Implementation
For the implementation of the Minimax algorithm I made a function of which the most important parameters are:
- The current position on the board
- The depth
- A boolean: maximizingplayer
At the first call of the Minimax function, we pass the member variable m_Depth as an argument to hold the depth and "false" for the maximizingplayer boolean because the AI is playing as black and black is the minimizing player.
In this function we first check if the depth is 0 or if the game is over so that we know if we still need to traverse the tree or not. If the depth is 0 or the game is over, I return the evaluation of that node.
If the depth has not been reached yet, we will check if it's the minizing player's turn (black) or the maximizing player's turn (white) based in the maximizing player boolean.
Minimizing player
If it's the minizing player's turn (black), we will look for the most negative evaluation possible starting from the current position.
In the code for black I have made a local variable minEvaluation, which holds a value of the most negative evaluation.
After this we loop over all possible moves black can make from the current position and we will recursively call the Minimax function for each move. As arguments for this function we pass the depth-1 and "true" as maximizingPlayer boolean because after this function call it's white's turn to move.
We put the result of this function call in a different local variable: currentEvaluation.
After this we will put the minEvaluation variable to the lowest value between minEvaluation and currentEvaluation (std::min).
Once we've evaluated all moves, we return minEvaluation.
Maximizing player
If it's the maximizing player's turn (white), we will look for the most positive value that can be found from the current position.
In this situation we will do the exact same as we did for black, but instead of looking for the most negative evaluation, we will hold the most positive evaluation in a local variable: maxEvaluation.
After each function call we will set that maxEvaluation variable to the highest value between maxEvaluation and currentEvaluation (std::max).
Best move
We also save the best move for black so that we can use that on the real-time board once we get back to the first call of the Minimax function.
Pruning
For Alpha-Beta pruning we will add to extra parameters to the Minimax-function: alpha and beta. Alpha is the worst possible score for white and beta is the worst possible score for black.
These values are recursively passed to Minimax and are adjusted to their better, and eventually, best possible values.
If beta is smaller than alpha, then black had a better move earlier in the tree, so the next move that needs to be evaluated can be ignored. This is called pruning. Nodes are pruned only when beta is smaller than alpha.
When we loop over all possible moves of a certain colour from the current position, we will break out of the loop when beta is smaller than alpha and so the next move is pruned.
Conclusion
The AI works in a very simplistic manner at the moment seeing as it only evaluates moves based on the possibility to capture the other's pieces.
This can be improved by adjusting the internal scoring system (eg. doubled pawns, developing pieces, castling, center control,..).
Sources